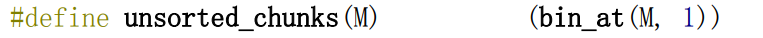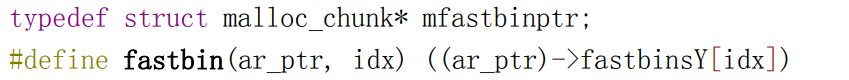structmalloc_state { /* Serialize access. */ //序列化访问 mutex_t mutex; /* Flags (formerly in max_fast). */ int flags; #if THREAD_STATS /* Statistics for locking. Only used if THREAD_STATS is defined. */ //用于锁定的数据,仅在THREAD_STATS定义时被使用 long stat_lock_direct, stat_lock_loop, stat_lock_wait; #endif /* Fastbins */ mfastbinptr fastbinsY[NFASTBINS]; /* Base of the topmost chunk -- not otherwise kept in a bin */ //top chunk的基地址不会被存储在其他bin中 mchunkptr top; /* The remainder from the most recent split of a small request */ //最近的一次分割请求产生的剩余块 mchunkptr last_remainder; /* Normal bins packed as described above */ //按描述的方式打包正常的bin mchunkptr bins[NBINS * 2 - 2]; /* Bitmap of bins */ //bin的位图 unsignedint binmap[BINMAPSIZE]; /* Linked list */ //链表 structmalloc_state *next; #ifdef PER_THREAD /* Linked list for free arenas. */ //用于空闲区域(arena)的链表 structmalloc_state *next_free; #endif /* Memory allocated from the system in this arena. */ //此区域中从系统分配的内存 INTERNAL_SIZE_T system_mem; INTERNAL_SIZE_T max_system_mem; };
Flags记录分配区的标志,bit0记录分配区是否至少有一个fast bin chunk,bit1用于记录分配区是否能返回连续的虚拟地址空间
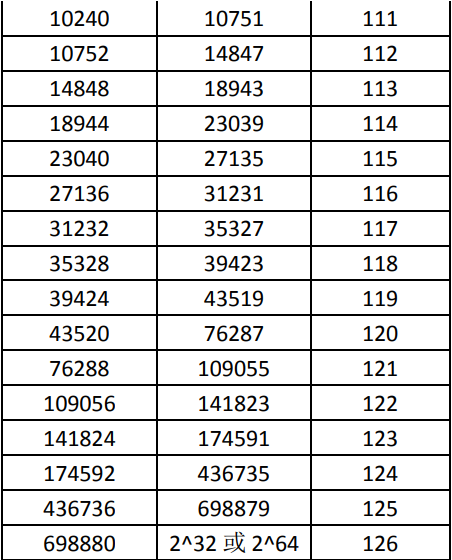
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
/* FASTCHUNKS_BIT held in max_fast indicates that there are probably some fastbin chunks. It is set true on entering a chunk into any fastbin, and cleared only in malloc_consolidate. The truth value is inverted so that have_fastchunks will be true upon startup (since statics are zero-filled), simplifying initialization checks. */ //FASTCHUNKS_BIT 存储在 max_fast 中,表示可能存在一些快速分配区(fastbin)的块。当一个块被放入任何一个快速分配区时,该标志会被设置为 true,并且仅在 malloc_consolidate 函数中被清除。 //该标志的真假值被反转,以便在启动时 have_fastchunks 为 true(因为静态变量会被初始化为零),从而简化初始化检查。 #define FASTCHUNKS_BIT (1U) #define have_fastchunks(M) (((M)->flags & FASTCHUNKS_BIT) == 0) #ifdef ATOMIC_FASTBINS #define clear_fastchunks(M) catomic_or (&(M)->flags, FASTCHUNKS_BIT) #define set_fastchunks(M) catomic_and (&(M)->flags, ~FASTCHUNKS_BIT) #else #define clear_fastchunks(M) ((M)->flags |= FASTCHUNKS_BIT) #define set_fastchunks(M) ((M)->flags &= ~FASTCHUNKS_BIT) #endif
/* NONCONTIGUOUS_BIT indicates that MORECORE does not return contiguous regions. Otherwise, contiguity is exploited in merging together, when possible, results from consecutive MORECORE calls. The initial value comes from MORECORE_CONTIGUOUS, but is changed dynamically if mmap is ever used as an sbrk substitute. */ //NONCONTIGUOUS_BIT 表示 MORECORE 不返回连续的内存区域。否则,会利用连续性,在可能的情况下,将连续的 MORECORE 调用的结果合并在一起。 //初始值来自 MORECORE_CONTIGUOUS,但如果 mmap 曾经被用作 sbrk 的替代品,这个值会被动态更改。 #define NONCONTIGUOUS_BIT (2U) #define contiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) == 0) #define noncontiguous(M) (((M)->flags & NONCONTIGUOUS_BIT) != 0) #define set_noncontiguous(M) ((M)->flags |= NONCONTIGUOUS_BIT) #define set_contiguous(M) ((M)->flags &= ~NONCONTIGUOUS_BIT)
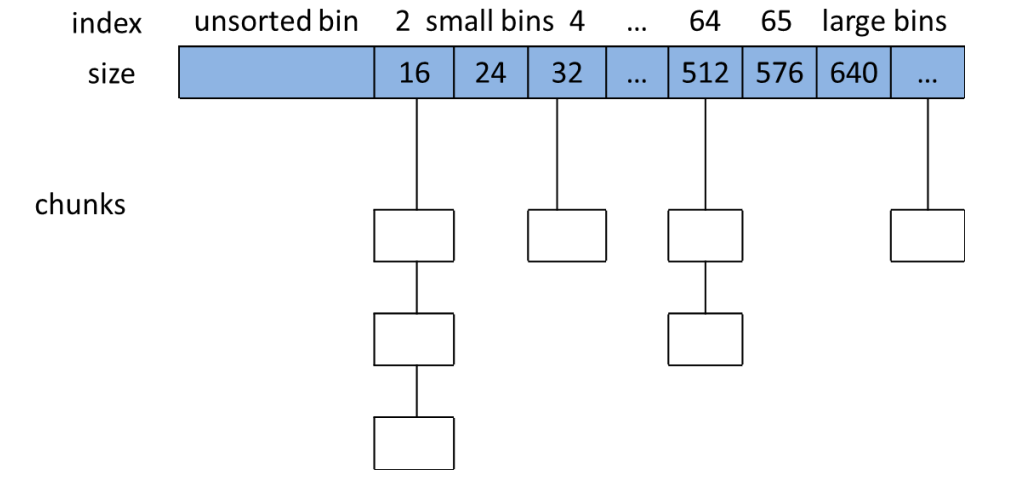
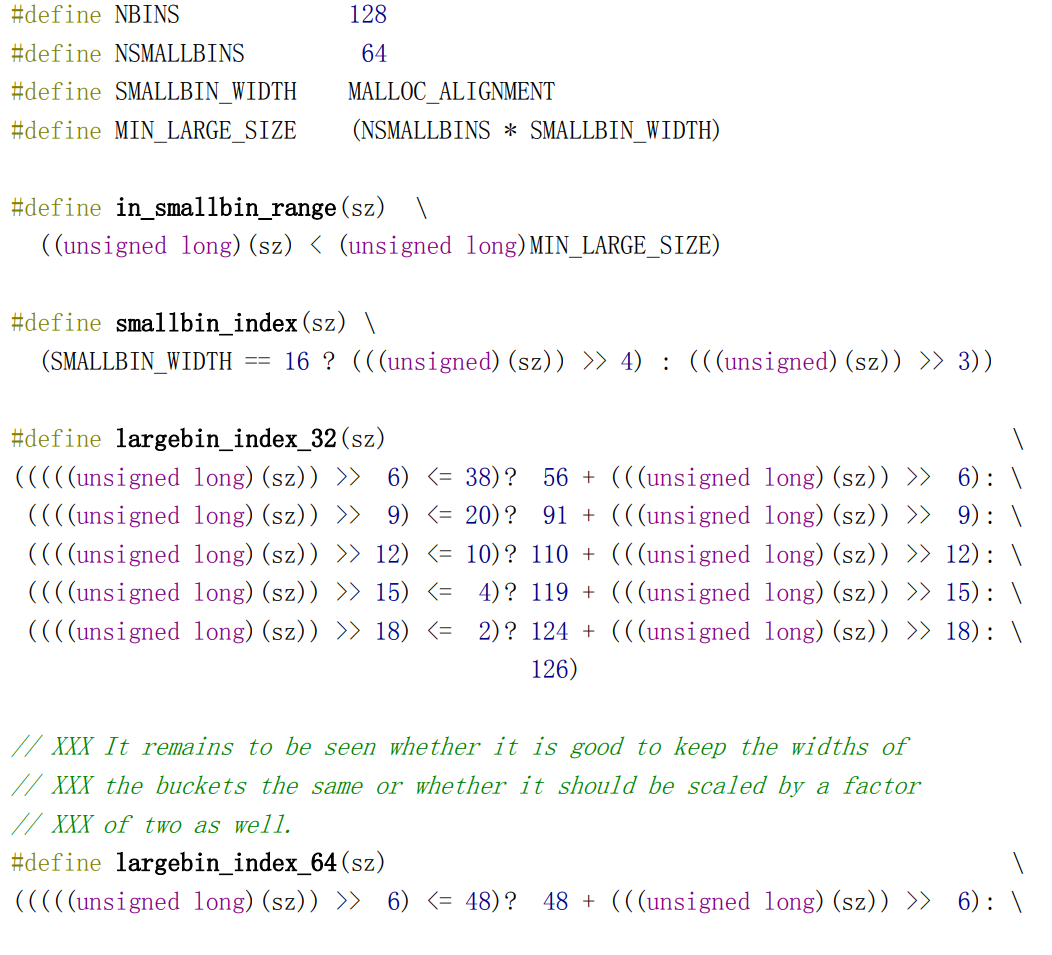
/* Binmap To help compensate for the large number of bins, a one-level index structure is used for bin-by-bin searching. `binmap' is a bitvector recording whether bins are definitely empty so they can be skipped over during during traversals. The bits are NOT always cleared as soon as bins are empty, but instead only when they are noticed to be empty during traversal in malloc. */ /* Conservatively use 32 bits per map word, even if on 64bit system */ /* Binmap(位图) 为了弥补 bin 数量较多的问题,这里使用了一种单级索引结构来进行逐个 bin 的搜索。binmap 是一个位向量,用于记录 bin 是否绝对为空,以便在遍历时跳过这些空的 bin。这些位并不是在 bin 变为空时立即清零,而是在 malloc 遍历时发现 bin 为空时才清除。*/ /* 保守地使用 32 位来表示每个映射单元,即使在 64 位系统上也是如此 */ #define BINMAPSHIFT 5 #define BITSPERMAP (1U << BINMAPSHIFT) #define BINMAPSIZE (NBINS / BITSPERMAP) #define idx2block(i) ((i) >> BINMAPSHIFT) #define idx2bit(i) ((1U << ((i) & ((1U << BINMAPSHIFT)-1)))) #define mark_bin(m,i) ((m)->binmap[idx2block(i)] |= idx2bit(i)) #define unmark_bin(m,i) ((m)->binmap[idx2block(i)] &= ~(idx2bit(i))) #define get_binmap(m,i) ((m)->binmap[idx2block(i)] & idx2bit(i))
structmalloc_par { /* Tunable parameters */ /* 可调节参数 */ unsignedlong trim_threshold; INTERNAL_SIZE_T top_pad; INTERNAL_SIZE_T mmap_threshold; #ifdef PER_THREAD INTERNAL_SIZE_T arena_test; INTERNAL_SIZE_T arena_max; #endif /* Memory map support */ /* 内存映射支持 */ int n_mmaps; int n_mmaps_max; int max_n_mmaps; /* the mmap_threshold is dynamic, until the user sets it manually, at which point we need to disable any dynamic behavior. */ /* mmap_threshold 是动态的,直到用户手动设置它为止。在用户手动设置后,我们需要禁用任何动态行为。*/ int no_dyn_threshold; /* Cache malloc_getpagesize */ /* 缓存 malloc_getpagesize 的值 */ unsignedint pagesize; /* Statistics */ /*数据*/ INTERNAL_SIZE_T mmapped_mem; INTERNAL_SIZE_T max_mmapped_mem; INTERNAL_SIZE_T max_total_mem; /* only kept for NO_THREADS *//* 仅用于 NO_THREADS 情况 */ /* First address handed out by MORECORE/sbrk. */ /* 通过 MORECORE/sbrk 分配的第一个地址。*/ char* sbrk_base; };
/* There are several instances of this struct ("arenas") in this malloc. If you are adapting this malloc in a way that does NOT use a static or mmapped malloc_state, you MUST explicitly zero-fill it before using. This malloc relies on the property that malloc_state is initialized to all zeroes (as is true of C statics). */ /* 在这个内存分配器中,存在多个这种结构体(“分配区”)。如果你正在以一种不使用静态分配或通过 mmap 映射的 malloc_state 的方式调整这个内存分配器,你必须在使用之前显式地将其清零。这个内存分配器依赖于 malloc_state 被初始化为全零的特性(这与 C 语言中静态变量的初始化行为一致)。 */ staticstructmalloc_statemain_arena; /* There is only one instance of the malloc parameters. */ /* 只有一个实例的内存分配参数。*/ staticstructmalloc_parmp_; /* Maximum size of memory handled in fastbins. */ /* fastbins 中处理的内存块的最大大小。*/ static INTERNAL_SIZE_T global_max_fast;
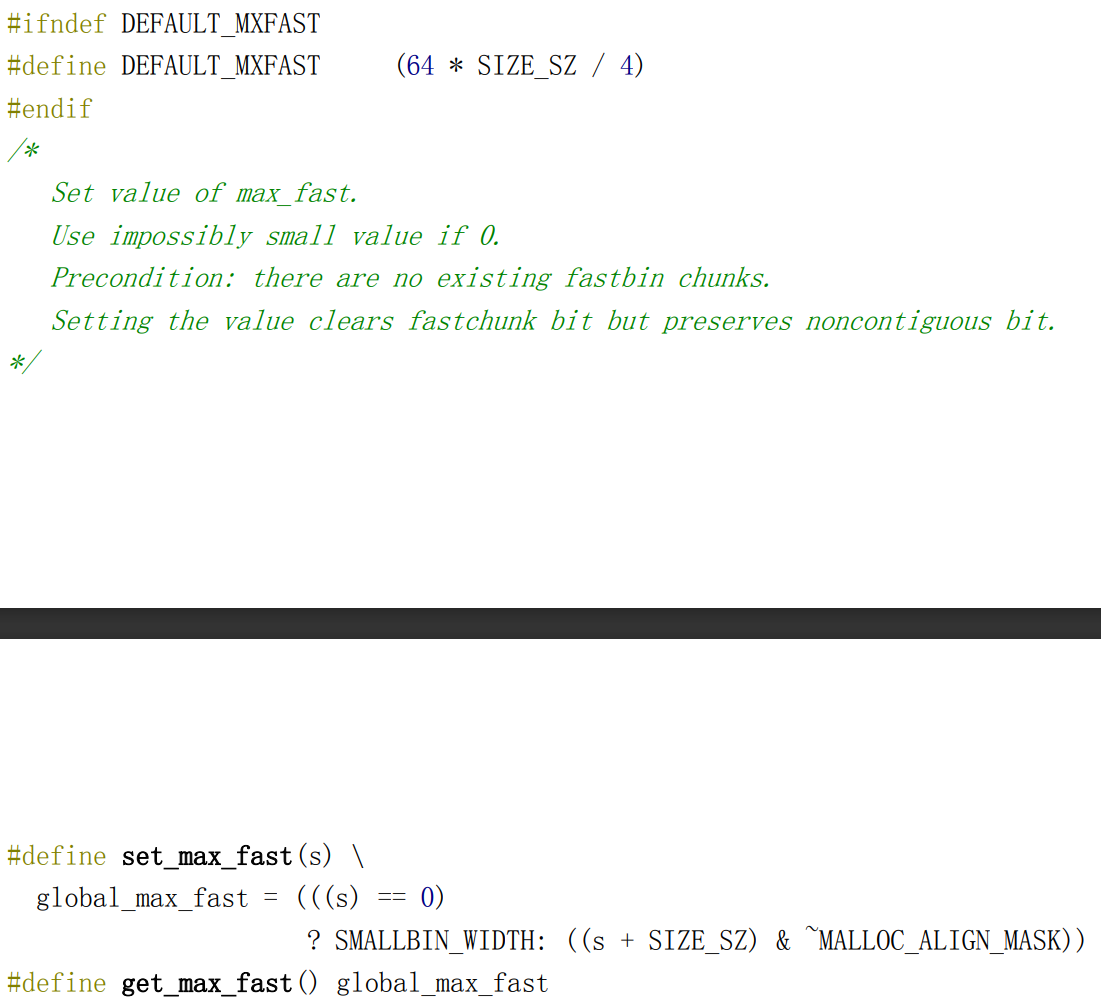
/* Initialize a malloc_state struct. This is called only from within malloc_consolidate, which needs be called in the same contexts anyway. It is never called directly outside of malloc_consolidate because some optimizing compilers try to inline it at all call points, which turns out not to be an optimization at all. (Inlining it in malloc_consolidate is fine though.) */ #if __STD_C staticvoidmalloc_init_state(mstate av) #else staticvoidmalloc_init_state(av) mstate av; #endif { int i; mbinptr bin; /* Establish circular links for normal bins */ for (i = 1; i < NBINS; ++i) { bin = bin_at(av,i); bin->fd = bin->bk = bin; } //设置非主分配区 #if MORECORE_CONTIGUOUS if (av != &main_arena) #endif set_noncontiguous(av); //初始化主分配区 if (av == &main_arena) set_max_fast(DEFAULT_MXFAST); //设置标志位 av->flags |= FASTCHUNKS_BIT; //初始化top chunk av->top = initial_top(av); }
victim = _int_malloc (ar_ptr, bytes); /* Retry with another arena only if we were able to find a usable arena before. */ //如果第一次分配失败,并分配区不为空,则尝试从另一分配区重新分配 if (!victim && ar_ptr != NULL) { LIBC_PROBE (memory_malloc_retry, 1, bytes); ar_ptr = arena_get_retry (ar_ptr, bytes);//尝试另一个可用分配区 victim = _int_malloc (ar_ptr, bytes);//再次调用分配的函数 }
//如果分配区不为空那就释放互斥锁(mutex) if (ar_ptr != NULL) (void) mutex_unlock (&ar_ptr->mutex);
mchunkptr victim; /* inspected/selected chunk(检查/选择的块) */ //victim:指针,指向当前正在检查或选择的内存块 INTERNAL_SIZE_T size; /* its size */ //size是当前内存块的大小 int victim_index; /* its bin index(它的bin索引) */ //=当前内存块所属的bin索引 mchunkptr remainder; /* remainder from a split (分割后的剩余部分)*/ //指针,指向分割后的剩余部分 unsignedlong remainder_size; /* its size */ //剩余部分大小
unsignedint block; /* bit map traverser (位图遍历器)*/ //block用来遍历位图 unsignedint bit; /* bit map traverser (位图遍历器)*/ //bit是另一个变量,用来遍历位图中的位 unsignedintmap; /* current word of binmap(当前binmap中的word) */ //map是当前正在处理的binmap中的一个字(word)
mchunkptr fwd; /* misc temp for linking(链接时的临时变量) */ //一个临时指针,用于链接 mchunkptr bck; /* misc temp for linking (链接时的临时变量)*/ //另一个临时指针,用于链接
constchar *errstr = NULL;
然后
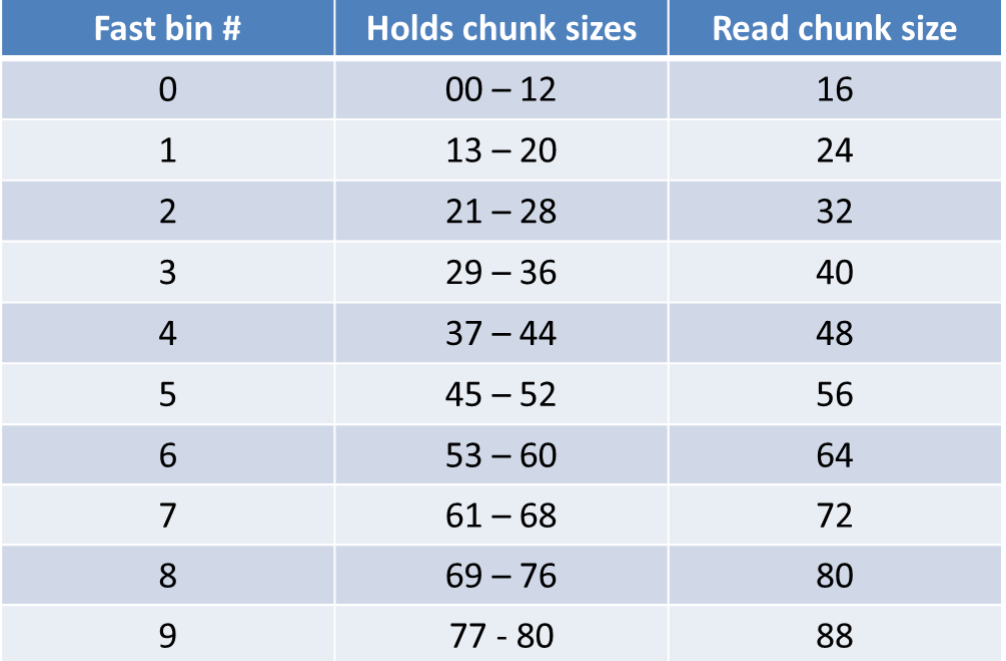
1 2 3 4 5 6 7 8 9 10
/* Convert request size to internal form by adding SIZE_SZ bytes overhead plus possibly more to obtain necessary alignment and/or to obtain a size of at least MINSIZE, the smallest allocatable size. Also, checked_request2size traps (returning 0) request sizes that are so large that they wrap around zero when padded and aligned. */
/* There are no usable arenas. Fall back to sysmalloc to get a chunk from mmap. */ /* 没有可用的分配区域(arena)。回退到 sysmalloc,通过 mmap 获取一块内存。 */ if (__glibc_unlikely (av == NULL))//检查是否有可用arena { //没有时 void *p = sysmalloc (nb, av); if (p != NULL) alloc_perturb (p, bytes); return p; }
/* If the size qualifies as a fastbin, first check corresponding bin. This code is safe to execute even if av is not yet initialized, so we can try it without checking, which saves some time on this fast path. */
/* If a small request, check regular bin. Since these "smallbins" hold one size each, no searching within bins is necessary. (For a large request, we need to wait until unsorted chunks are processed to find best fit. But for small ones, fits are exact anyway, so we can check now, which is faster.) */
if (in_smallbin_range (nb))//检查是否属于smallbin范围内 { idx = smallbin_index (nb);//计算smallbin索引 bin = bin_at (av, idx);//获取smallbin指针
if ((victim = last (bin)) != bin)//尝试从smallbin中分配内存 { if (victim == 0) /* initialization check(初始化检查) */ malloc_consolidate (av);//如果分配区还没初始化就初始化,这是初始化函数 else { bck = victim->bk; if (__glibc_unlikely (bck->fd != victim))//检查双向链表完整性 { errstr = "malloc(): smallbin double linked list corrupted"; goto errout; } set_inuse_bit_at_offset (victim, nb);//标记内存块已使用和设置内存块大小 //接下来两行是更新双向链表指针 bin->bk = bck; bck->fd = bin;
/* If this is a large request, consolidate fastbins before continuing. While it might look excessive to kill all fastbins before even seeing if there is space available, this avoids fragmentation problems normally associated with fastbins. Also, in practice, programs tend to have runs of either small or large requests, but less often mixtures, so consolidation is not invoked all that often in most programs. And the programs that it is called frequently in otherwise tend to fragment. */
/* If a small request, try to use last remainder if it is the only chunk in unsorted bin. This helps promote locality for runs of consecutive small requests. This is the only exception to best-fit, and applies only when there is no exact fit for a small chunk. */ /* 如果是一个小请求,尝试使用上一次的剩余部分(remainder),前提是无序链表(unsorted bin)中只有一个块。这有助于提升连续小请求的局部性。这是最佳拟合(best-fit)策略的唯一例外,仅适用于没有精确匹配的小块。 */
/* maintain large bins in sorted order */ if (fwd != bck) { /* Or with inuse bit to speed comparisons */ size |= PREV_INUSE; /* if smaller than smallest, bypass loop below */ assert ((bck->bk->size & NON_MAIN_ARENA) == 0); if ((unsignedlong) (size) < (unsignedlong) (bck->bk->size)) { fwd = bck; bck = bck->bk;
/* If a large request, scan through the chunks of current bin in sorted order to find smallest that fits. Use the skip list for this. */
if (!in_smallbin_range (nb)) { bin = bin_at (av, idx);//获取头指针
/* skip scan if empty or largest chunk is too small *///跳过链表为空或第一个chunk大小小于请求大小 if ((victim = first (bin)) != bin && (unsignedlong) (victim->size) >= (unsignedlong) (nb)) { //寻找大小合适的chunk victim = victim->bk_nextsize; while (((unsignedlong) (size = chunksize (victim)) < (unsignedlong) (nb))) victim = victim->bk_nextsize;
/* Avoid removing the first entry for a size so that the skip list does not have to be rerouted. */ //若找到的chunk不是最后一个且与下一个chunk大小相同就跳过这个chunk if (victim != last (bin) && victim->size == victim->fd->size) victim = victim->fd;
/* Search for a chunk by scanning bins, starting with next largest bin. This search is strictly by best-fit; i.e., the smallest (with ties going to approximately the least recently used) chunk that fits is selected.
The bitmap avoids needing to check that most blocks are nonempty. The particular case of skipping all bins during warm-up phases when no chunks have been returned yet is faster than it might look. */ /* * 通过扫描 bins 来搜索合适的 chunk,从下一个较大的 bin 开始。 * 这种搜索严格遵循最佳拟合策略;即选择最小的(如果有多个大小相同的 chunk,则选择最近最少使用的)chunk。 * * 位图(binmap)避免了检查大多数块是否为空的需要。 * 在没有返回任何 chunk 的热启动阶段,跳过所有 bins 的情况比看起来要快。 */
++idx;//从下一个bin开始搜索 bin = bin_at (av, idx);//获取当前bin的指针 block = idx2block (idx);//计算当前bin所在块索引 map = av->binmap[block];//获取当前块的binmap bit = idx2bit (idx);//获取当前bin对应的位
for (;; ) { /* Skip rest of block if there are no more set bits in this block. */ if (bit > map || bit == 0) { do//若超出bins的范围就跳到使用top chunk { if (++block >= BINMAPSIZE) /* out of bins */ goto use_top; } while ((map = av->binmap[block]) == 0);
bin = bin_at (av, (block << BINMAPSHIFT)); bit = 1; }
/* Advance to bin with set bit. There must be one. */ while ((bit & map) == 0)//找到第一个非空bin { bin = next_bin (bin); bit <<= 1; assert (bit != 0); }
/* Inspect the bin. It is likely to be non-empty */ victim = last (bin);//获取bin最后一个chunk
/* If a false alarm (empty bin), clear the bit. */ if (victim == bin)//若bin为空 { av->binmap[block] = map &= ~bit; /* Write through *///清除对应的位 bin = next_bin (bin); bit <<= 1; }
else//若不为空 { size = chunksize (victim);//获取大小
/* We know the first chunk in this bin is big enough to use. */ assert ((unsignedlong) (size) >= (unsignedlong) (nb));
remainder_size = size - nb;//剩余部分
/* unlink */ unlink (av, victim, bck, fwd);
/* Exhaust */ if (remainder_size < MINSIZE)//剩余<MINSIZE { set_inuse_bit_at_offset (victim, size);//标记整个chunk为已使用 if (av != &main_arena) victim->size |= NON_MAIN_ARENA; }
use_top: /* If large enough, split off the chunk bordering the end of memory (held in av->top). Note that this is in accord with the best-fit search rule. In effect, av->top is treated as larger (and thus less well fitting) than any other available chunk since it can be extended to be as large as necessary (up to system limitations).
We require that av->top always exists (i.e., has size >= MINSIZE) after initialization, so if it would otherwise be exhausted by current request, it is replenished. (The main reason for ensuring it exists is that we may need MINSIZE space to put in fenceposts in sysmalloc.) */
/* When we are using atomic ops to free fast chunks we can get here for all block sizes. */ elseif (have_fastchunks (av))//合并fastbins后再次尝试分配 { malloc_consolidate (av);//合并fastbins /* restore original bin index */ if (in_smallbin_range (nb)) idx = smallbin_index (nb); else idx = largebin_index (nb); }
/* Little security check which won't hurt performance: the allocator never wrapps around at the end of the address space. Therefore we can exclude some size values which might appear here by accident or by "design" from some intruder. */ /* 一个不会影响性能的小型安全检查:分配器永远不会在地址空间的末尾回绕。因此,我们可以排除一些可能偶然出现或被“设计”出来的大小值,这些值可能来自某些入侵者。 */ if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0) || __builtin_expect (misaligned_chunk (p), 0))//指针是否合法||内存块地址是否符合对其要求 { errstr = "free(): invalid pointer"; errout: if (!have_lock && locked) (void) mutex_unlock (&av->mutex); malloc_printerr (check_action, errstr, chunk2mem (p), av); return; } /* We know that each chunk is at least MINSIZE bytes in size or a multiple of MALLOC_ALIGNMENT. */ if (__glibc_unlikely (size < MINSIZE || !aligned_OK (size)))//内存块大小<MINSIZE||内存块大小是否符合对其要求 { errstr = "free(): invalid size"; goto errout; }
if ((unsignedlong)(size) <= (unsignedlong)(get_max_fast ())//看是否在fastbin范围内
#if TRIM_FASTBINS /* If TRIM_FASTBINS set, don't place chunks bordering top into fastbins */ /* 如果定义了 TRIM_FASTBINS,不要将紧邻 top chunk 的 chunk 放入 fastbins。 */ && (chunk_at_offset(p, size) != av->top) #endif ) {
if (__builtin_expect (chunk_at_offset (p, size)->size <= 2 * SIZE_SZ, 0)//检查洗一个chunk大小是不是<=2*SIZE_SZ || __builtin_expect (chunksize (chunk_at_offset (p, size))//或大于分配区总内存 >= av->system_mem, 0)) { /* We might not have a lock at this point and concurrent modifications of system_mem might have let to a false positive. Redo the test after getting the lock. */ if (have_lock || ({ assert (locked == 0);//获取锁,重新检查 mutex_lock(&av->mutex); locked = 1; chunk_at_offset (p, size)->size <= 2 * SIZE_SZ || chunksize (chunk_at_offset (p, size)) >= av->system_mem; })) { errstr = "free(): invalid next size (fast)"; goto errout; } if (! have_lock)//释放锁 { (void)mutex_unlock(&av->mutex); locked = 0; } }
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */ //原子操作将chunk插入fastbin mchunkptr old = *fb, old2; unsignedint old_idx = ~0u; do { /* Check that the top of the bin is not the record we are going to add (i.e., double free). */ /* 检查 fastbin 的顶部是否是当前要插入的 chunk(即双重释放)。 */ if (__builtin_expect (old == p, 0)) { errstr = "double free or corruption (fasttop)"; goto errout; } /* Check that size of fastbin chunk at the top is the same as size of the chunk that we are adding. We can dereference OLD only if we have the lock, otherwise it might have already been deallocated. See use of OLD_IDX below for the actual check. */ //检查fastbin顶部chunk大小是否与当前chunk大小一致 if (have_lock && old != NULL) old_idx = fastbin_index(chunksize(old)); p->fd = old2 = old; } while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2)) != old2);
/* Lightweight tests: check whether the block is already the top block. */ if (__glibc_unlikely (p == av->top))//检查当前内存块是不是分配区的topchunk { errstr = "double free or corruption (top)"; goto errout; } /* Or whether the next chunk is beyond the boundaries of the arena. */ //检查下个chunk是不是超出分配区的边界 if (__builtin_expect (contiguous (av) && (char *) nextchunk >= ((char *) av->top + chunksize(av->top)), 0)) { errstr = "double free or corruption (out)"; goto errout; } /* Or whether the block is actually not marked used. */ //检查下个快的‘前一块是否使用标志位’设置没 if (__glibc_unlikely (!prev_inuse(nextchunk))) { errstr = "double free or corruption (!prev)"; goto errout; }
/* Place the chunk in unsorted chunk list. Chunks are not placed into regular bins until after they have been given one chance to be used in malloc. */
/* If the chunk borders the current high end of memory, consolidate into top */ //如果内存块与top chunk相邻,就合并到top chunk else { size += nextsize; set_head(p, size | PREV_INUSE); av->top = p; check_chunk(av, p); }
/* If freeing a large space, consolidate possibly-surrounding chunks. Then, if the total unused topmost memory exceeds trim threshold, ask malloc_trim to reduce top.
Unless max_fast is 0, we don't know if there are fastbins bordering top, so we cannot tell for sure whether threshold has been reached unless fastbins are consolidated. But we don't want to consolidate on each free. As a compromise, consolidation is performed if FASTBIN_CONSOLIDATION_THRESHOLD is reached. */
if ((unsignedlong)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD) //当前释放的大小超过FASTBIN_CONSOLIDATION_THRESHOLD进入分支 { if (have_fastchunks(av)) malloc_consolidate(av);//合并fastbin中内存块
if (av == &main_arena)//看是否要修剪top chunk { #ifndef MORECORE_CANNOT_TRIM if ((unsignedlong)(chunksize(av->top)) >= (unsignedlong)(mp_.trim_threshold))//看top chunk是不是超过了修剪阈值 systrim(mp_.top_pad, av); #endif } else//对于非主分配区 { /* Always try heap_trim(), even if the top chunk is not large, because the corresponding heap might go away. */ /* 即使顶部块不大,也尝试调用 heap_trim(),因为对应的堆可能会被释放。 */ heap_info *heap = heap_for_ptr(top(av));
victim = _int_malloc (ar_ptr, bytes); /* Retry with another arena only if we were able to find a usable arena before. */ if (!victim && ar_ptr != NULL) { LIBC_PROBE (memory_malloc_retry, 1, bytes); ar_ptr = arena_get_retry (ar_ptr, bytes); victim = _int_malloc (ar_ptr, bytes); }
if (ar_ptr != NULL) __libc_lock_unlock (ar_ptr->mutex);
/* We overlay this structure on the user-data portion of a chunk when the chunk is stored in the per-thread cache. */ /* 当一个内存块(chunk)存储在线程本地缓存(per-thread cache)中时, 我们将这个结构体覆盖在内存块的用户数据部分。 */ typedefstructtcache_entry//用于管理空闲chunk的结构体 { structtcache_entry *next;//指向下一个空闲chunk } tcache_entry;
/* There is one of these for each thread, which contains the per-thread cache (hence "tcache_perthread_struct"). Keeping overall size low is mildly important. Note that COUNTS and ENTRIES are redundant (we could have just counted the linked list each time), this is for performance reasons. */ /* 每个线程都有一个这样的结构体,它包含了线程本地缓存 (因此命名为 "tcache_perthread_struct")。保持整体大小较小是较为重要的。 注意,COUNTS 和 ENTRIES 是冗余的(我们本可以每次都遍历链表来计数), 这是出于性能考虑。 */ typedefstructtcache_perthread_struct//每个线程的teache数据结构 { char counts[TCACHE_MAX_BINS];//记录每个bin中空闲chunk数量,TCACHE_MAX_BINS:tcache中最大bin数量 tcache_entry *entries[TCACHE_MAX_BINS];//每个元素是指向tcache_entry链表的指针 } tcache_perthread_struct;
/* If the size qualifies as a fastbin, first check corresponding bin. This code is safe to execute even if av is not yet initialized, so we can try it without checking, which saves some time on this fast path. */
if (victim != NULL) { if (SINGLE_THREAD_P)//单线程直接移除(更新fastbin链表头) *fb = victim->fd; else//多线程,用上面那个宏安全移除 REMOVE_FB (fb, pp, victim); if (__glibc_likely (victim != NULL)) { size_t victim_idx = fastbin_index (chunksize (victim)); if (__builtin_expect (victim_idx != idx, 0)) malloc_printerr ("malloc(): memory corruption (fast)"); check_remalloced_chunk (av, victim, nb); #if USE_TCACHE//新加的,若启用tcache且其没满,就将fastbin中内存块移到tcache中 /* While we're here, if we see other chunks of the same size, stash them in the tcache. */ size_t tc_idx = csize2tidx (nb); if (tcache && tc_idx < mp_.tcache_bins) { mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks. */ while (tcache->counts[tc_idx] < mp_.tcache_count && (tc_victim = *fb) != NULL) { if (SINGLE_THREAD_P) *fb = tc_victim->fd; else { REMOVE_FB (fb, pp, tc_victim); if (__glibc_unlikely (tc_victim == NULL)) break; } tcache_put (tc_victim, tc_idx); } } #endif void *p = chunk2mem (victim); alloc_perturb (p, bytes); return p; } } }
/* If a small request, check regular bin. Since these "smallbins" hold one size each, no searching within bins is necessary. (For a large request, we need to wait until unsorted chunks are processed to find best fit. But for small ones, fits are exact anyway, so we can check now, which is faster.) */
if (in_smallbin_range (nb))//移除内存块 { idx = smallbin_index (nb); bin = bin_at (av, idx);
if ((victim = last (bin)) != bin) { bck = victim->bk; if (__glibc_unlikely (bck->fd != victim)) malloc_printerr ("malloc(): smallbin double linked list corrupted"); set_inuse_bit_at_offset (victim, nb); bin->bk = bck; bck->fd = bin;
if (av != &main_arena)//非主分配区 set_non_main_arena (victim); check_malloced_chunk (av, victim, nb); #if USE_TCACHE//新加的 /* While we're here, if we see other chunks of the same size, stash them in the tcache. */ size_t tc_idx = csize2tidx (nb); if (tcache && tc_idx < mp_.tcache_bins) { mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks over. */ while (tcache->counts[tc_idx] < mp_.tcache_count && (tc_victim = last (bin)) != bin) { if (tc_victim != 0) { bck = tc_victim->bk; set_inuse_bit_at_offset (tc_victim, nb); if (av != &main_arena) set_non_main_arena (tc_victim); bin->bk = bck; bck->fd = bin;
#if USE_TCACHE /* Fill cache first, return to user only if cache fills. We may return one of these chunks later. */ if (tcache_nb && tcache->counts[tc_idx] < mp_.tcache_count)//满足tcache { tcache_put (victim, tc_idx);//放到tcache中 return_cached = 1; continue; } else { #endif
#if USE_TCACHE /* If we've processed as many chunks as we're allowed while filling the cache, return one of the cached ones. */ ++tcache_unsorted_count;//计数已经处理的内存块 if (return_cached && mp_.tcache_unsorted_limit > 0 && tcache_unsorted_count > mp_.tcache_unsorted_limit)//判断填没填满 { return tcache_get (tc_idx); } #endif
大致意思: 在处理 unsorted bin 中的内存块时,如果已经处理了足够多的内存块(用于填充 tcache),则直接从 tcache 中返回一个内存块给用户。
#if USE_TCACHE { size_t tc_idx = csize2tidx (size); if (tcache != NULL && tc_idx < mp_.tcache_bins) { /* Check to see if it's already in the tcache. */ tcache_entry *e = (tcache_entry *) chunk2mem (p);
/* This test succeeds on double free. However, we don't 100% trust it (it also matches random payload data at a 1 in 2^<size_t> chance), so verify it's not an unlikely coincidence before aborting. */ if (__glibc_unlikely (e->key == tcache)) { tcache_entry *tmp; LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx); for (tmp = tcache->entries[tc_idx]; tmp; tmp = tmp->next) if (tmp == e) malloc_printerr ("free(): double free detected in tcache 2"); /* If we get here, it was a coincidence. We've wasted a few cycles, but don't abort. */ }
/* The value of tcache_key does not really have to be a cryptographically secure random number. It only needs to be arbitrary enough so that it does not collide with values present in applications. If a collision does happen consistently enough, it could cause a degradation in performance since the entire list is checked to check if the block indeed has been freed the second time. The odds of this happening are exceedingly low though, about 1 in 2^wordsize. There is probably a higher chance of the performance degradation being due to a double free where the first free happened in a different thread; that's a case this check does not cover. */ staticvoid tcache_key_initialize(void) { if (__getrandom (&tcache_key, sizeof(tcache_key), GRND_NONBLOCK) != sizeof (tcache_key)) { tcache_key = random_bits (); #if __WORDSIZE == 64 tcache_key = (tcache_key << 32) | random_bits (); #endif } }
if (__glibc_unlikely (e->key == tcache_key)) { tcache_entry *tmp; size_t cnt = 0; LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx); for (tmp = tcache->entries[tc_idx]; tmp; tmp = REVEAL_PTR (tmp->next), ++cnt)//解密 { if (cnt >= mp_.tcache_count)//检查链表长度是不是超过了最大长度 malloc_printerr ("free(): too many chunks detected in tcache"); if (__glibc_unlikely (!aligned_OK (tmp)))//检查对齐 malloc_printerr ("free(): unaligned chunk detected in tcache 2"); if (tmp == e)//检查双重释放 malloc_printerr ("free(): double free detected in tcache 2"); /* If we get here, it was a coincidence. We've wasted a few cycles, but don't abort. */ } }
加密及解密宏
1 2 3 4 5 6 7 8 9 10 11 12
/* Safe-Linking: Use randomness from ASLR (mmap_base) to protect single-linked lists of Fast-Bins and TCache. That is, mask the "next" pointers of the lists' chunks, and also perform allocation alignment checks on them. This mechanism reduces the risk of pointer hijacking, as was done with Safe-Unlinking in the double-linked lists of Small-Bins. It assumes a minimum page size of 4096 bytes (12 bits). Systems with larger pages provide less entropy, although the pointer mangling still works. */ #define PROTECT_PTR(pos, ptr) \ ((__typeof (ptr)) ((((size_t) pos) >> 12) ^ ((size_t) ptr))) #define REVEAL_PTR(ptr) PROTECT_PTR (&ptr, ptr)